
The source of every data science project is a dataset or even multiple. In general, scientists
prefer to share data using a spreadsheet. This allows to quickly explore, enter and modify data.
Software developers on the other hand, prefer to build around properly designed schemes and backends
that ensure data integrity. Whoever wins this battle decides where the data is stored: in a type of
spreadsheet file or in some kind of database. And the loser? He/she has to struggle with the
problems that come with it. Until now. A new era has begun: editbl to the rescue!
editbl is an R package that allows you to do exactly
what is says: ‘edit tibbles*‘. It takes the cruxes out of
CRUD and is resistant to growing
complexity of the data. You can use it to quickly modify some tabular data when writing scripts, but
it can also serve as a building block for more complex applications.
*For those not familiar with R, tbl or tibble is basically just the
dplyr way of pronouncing ‘table’.
Get started
Choose a dataset and use eDT to interactively explore and modify it!
modifiedData <- editbl::eDT(mtcars)
print(modifiedData)
Or just run what could be your next database frontend:
editbl::runDemoApp()
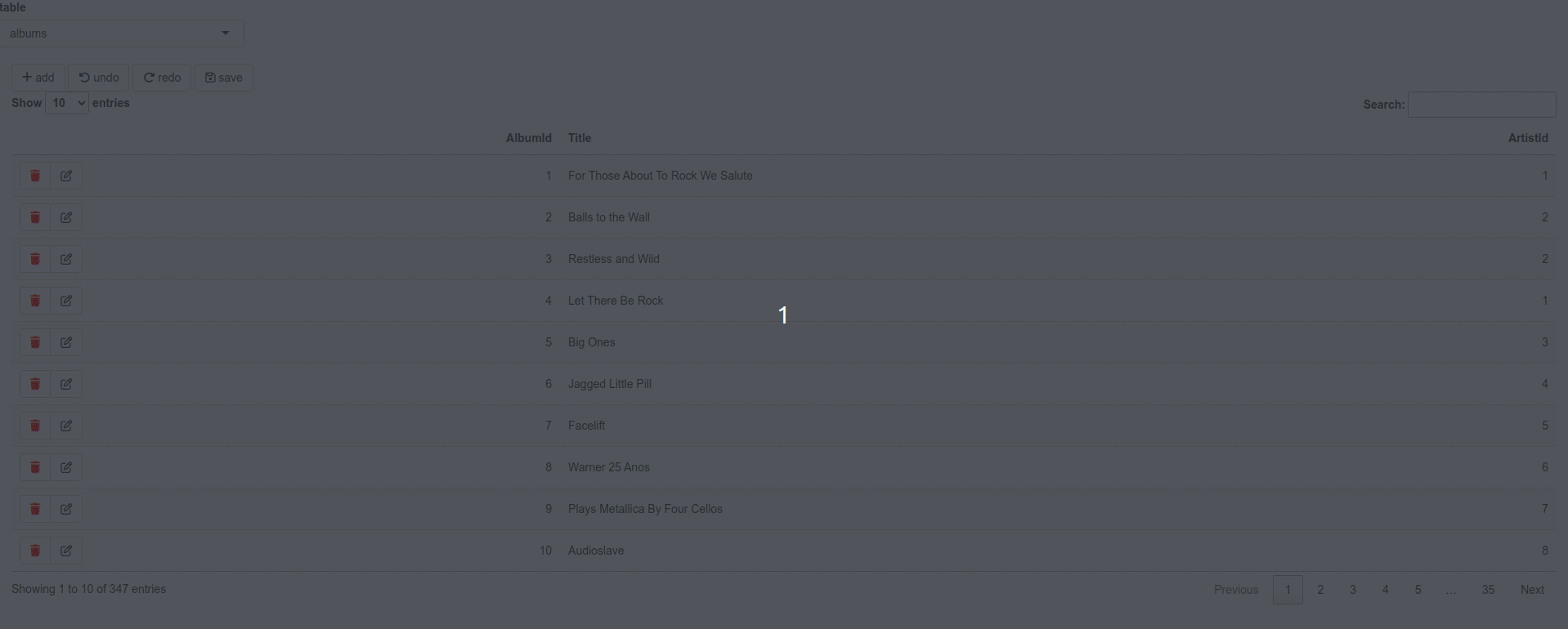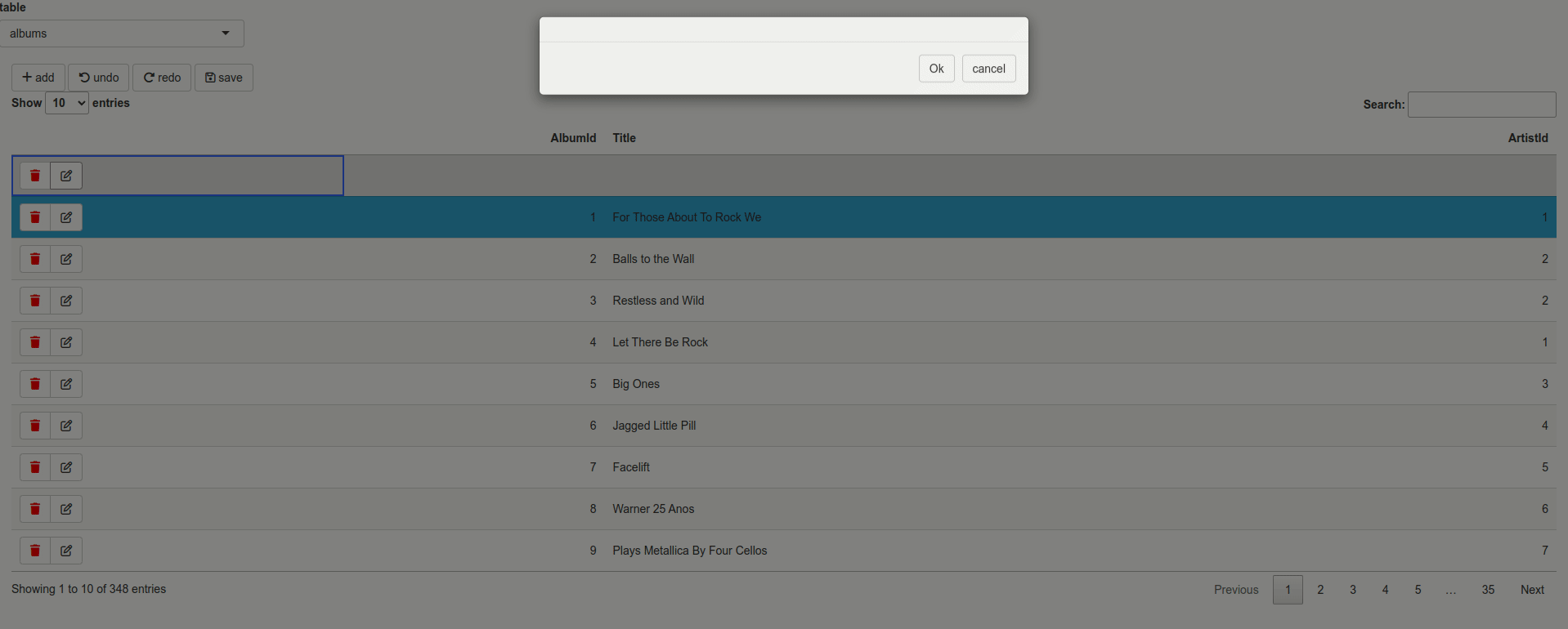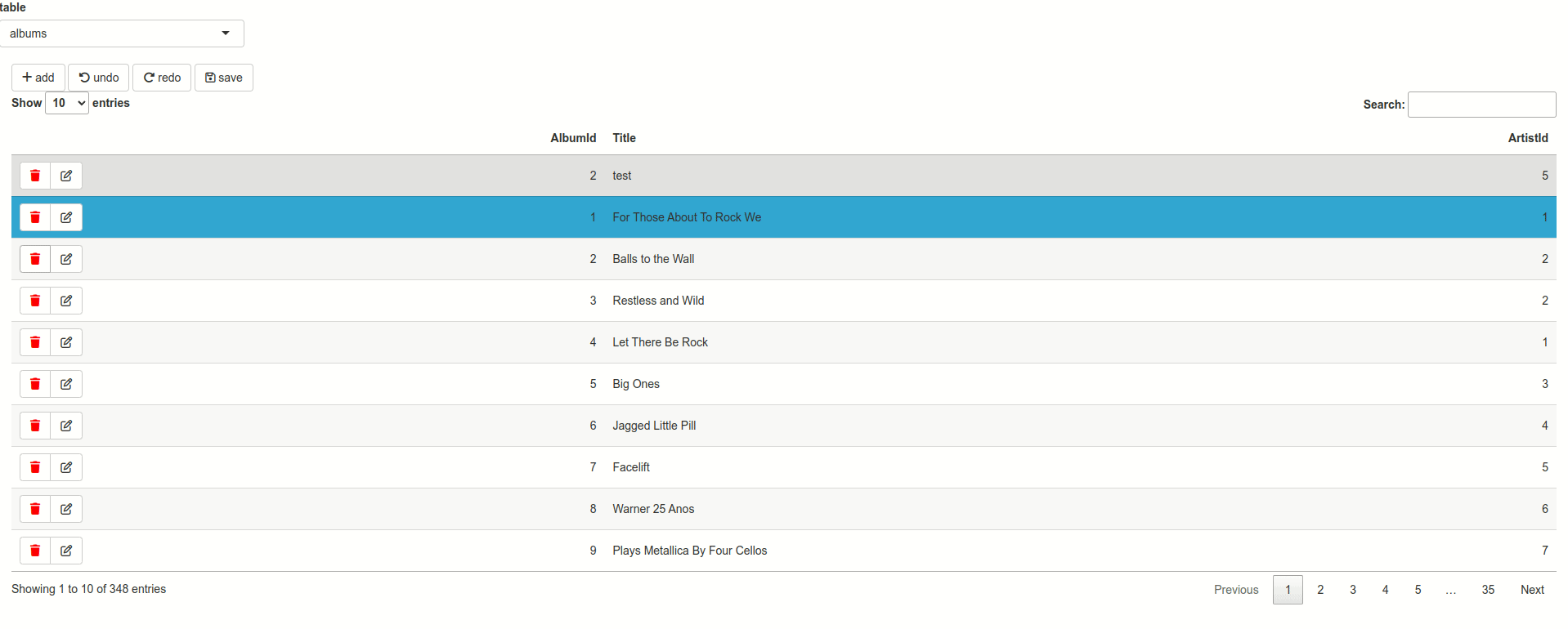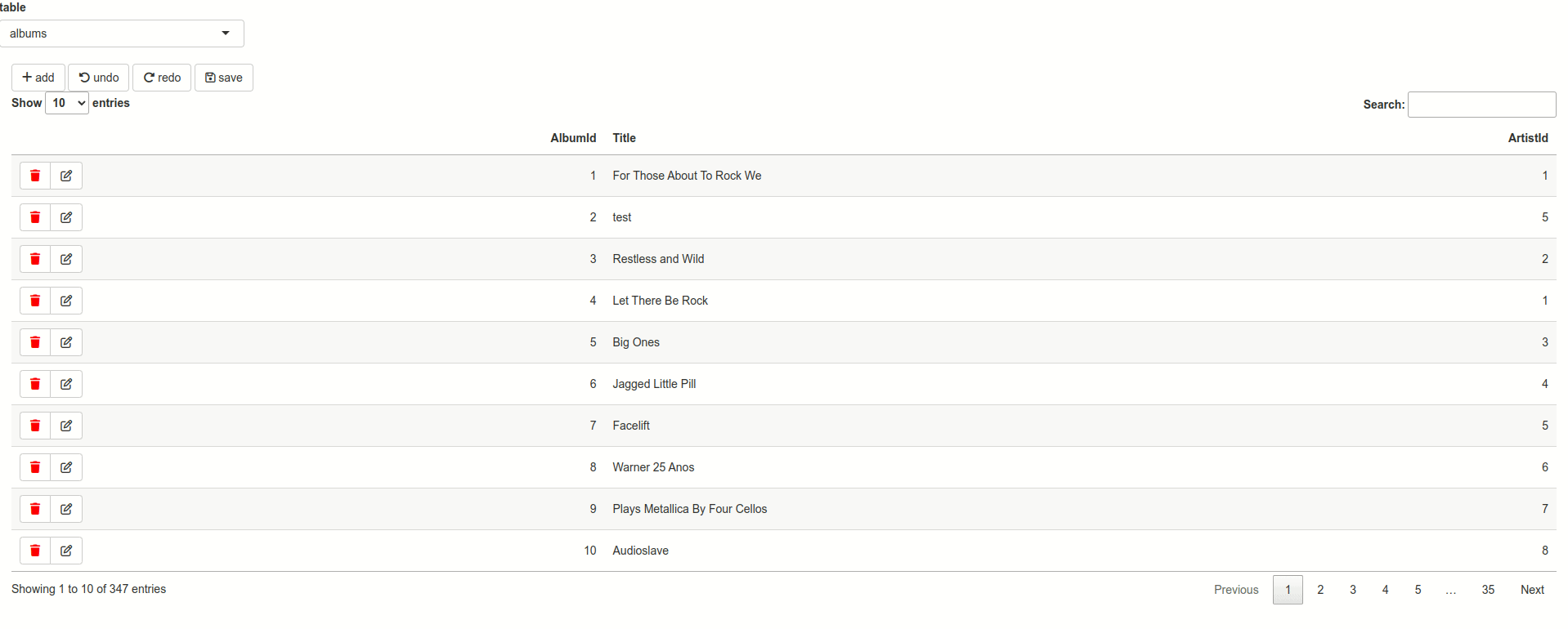
Data simplicity vs data integrity
We all remember that one big project having at its core functioning one or more spreadsheet files. Spreadsheets are just the easiest way to store and share data. Problems however slowly kick in as soon as software is built around them while the data evolves. Adding an extra column? Software breaks. Changing column names? Software breaks. Placing some comments? Removing an empty row? Using special characters? Changing the date format? Changing between ‘idk’, ‘NA’, ‘NAN’, ‘unkown’ or “ for missing data? The file becomes too big? … You guessed it right: software breaks. It is only a matter of time before someone makes changes in the spreadsheet that break the software. At this point, the developer has no clue which changes were made that cause the problem. After a while you realize spreadsheets might not have been the best way to store data. Unfortunately, by that time they have already rooted themselves deep into your system and require a substantial code change to replace them with a more robust backend. The speed of developing goes down and the data is locked where nobody dares to modify it.
We have also been in situations where data lives somewhere in the cloud. In a big centralized and well-designed system, like a relational database. With highly normalized tables, indexes and all proper constraints software developers can dream of. The software around it loves the robustness and data integrity while scientists struggle with all the meaningless ‘x_id’, ‘y_id’, ‘z_id’ columns popping up. The data has been reduced to tiny normalized tables with nothing more than numbers or UUID’s. The only way to get data into your system is through some customized API on which you need to study for weeks to understand it properly. If you are a bit luckier, maybe someone designed already a proper CRUD application or some input forms around it. However, these applications often take quite some time to develop and adjust. The speed of developing goes down and the data is locked where nobody can modify it.
So, how do you find some middle ground? How can you have both the ease of editing a spreadsheet and
the integrity of a robust backend without having to waste hours on developing a customized CRUD
application yourself? This is where editbl helps you out.
Features
Multiple backends are supported
Tabular data from various backends is supported, because data manipulation is performed by
dplyr. editbl does not care if your
table exists in SQLite, Postgres, Parquet or is just a simple in-memory data.frame. This implies
you can easily switch backends, while the frontend stays the same. No custom methods needed. No
worries about sql injection. No worries about typecasting.
Shiny integration
The core function of editable is called eDT and basically is a shiny
module. It is set up in a way that all of its
arguments can be reactive. This way it is easily integrated in any
shiny application.
Customizable frontend
editbl builds upon the DT package as
light weight as possible. It makes use of all tricks and extensions from DT to customize the
frontend to your needs. So, for users of the DT package, there is almost nothing new to learn, but
it comes with the benefits described below.
Spreadsheet feeling
Double click on a cell to edit it. Drag the content of cells across multiple rows. Sort by columns or search in the table. Undo, redo and save changes. All as easy as in a spreadsheet.
Constrainted inputs
While editing can be as easy as in a spreadsheet, it is sometimes necessary to put constraints on
it. editbl follows the database concept of foreign keys for applying constraints. Whenever the
user violates a constraint, editbl will stand its ground. When using a modal to edit your row, you
will also get nudged in the right direction with options from these foreign tables.
Hiding surrogate keys
Often the data in your backend is normalized and split into smaller tables. Sometimes these table
use surrogate keys that are very useful from a backend perspective, but useless to someone editing
the table. editbl has some tricks that allow you to hide these keys for users, while still
available in the backend.
Very big datasets
editbl saves modifications by joining with the key columns. This is in contrast with most other
CRUD packages that use row numbers for updating an in-memory data.frame. For editbl there is no
need to have all data in memory. You can focus on a subset of rows to be modified by pre-filtering
with some dplyr code. Note that this key benefit comes with one key assumption: your table needs a
key. Or less key-ish formulated: all rows in your table need to be unique. Which is probably already
the case if you have a properly designed backend.
Transactional commits
Changes are only stored when clicking ‘save’ and are executed all at once. This because saving
changes immediately to your backend, can introduce quite some overhead. In addition, editbl
highlights changes while editing and summarizes all changes before actually saving. This delay also
makes sure you only adjusted what’s needed on the backend. This makes editbl suitable for making a
lot of changes to the data at once, in a spreadsheet manner.
Undo/redo
Because what is a CRUD application without these buttons?
Further reading
While editbl tries to be a ‘one size fits all’ solution, it might not necessarily be ‘the best’
solution to your problem. Want to know more about the capabilities of shiny in replacing
spreadsheets? Check out this excellent blog
post from Appsilon a couple
of years ago.
Still not found what you needed, but as enthousiastic as us about editbl? Feel free
to contribute to this project on https://github.com/openanalytics/editbl.
